Introduction to Neural Architecture Search (Reinforcement Learning approach)
Author: Hamdi M Abed
AI that creates AI, that is what first people described automated machine learning (AutoML). But is it really like that? AutoML gained notable attention since 2016 when Google brain revealed their first Neural Architecture Search (NAS) publication by Quac Le and Barret Zoph , which was used in several applications. The idea is to generate some candidate children networks, train them, optimize it’s accuracy until successfully select the best architecture for some certain task. In this article, we will discuss the NAS based on reinforcement learning.
Introduction
During the last 7 years, Machine learning was dramatically trending, especially neural network approaches. It has been heavily used in computer vision, text and speech processing, and recently in games solving using reinforcement learning. However, choosing a neural network architecture manually is an exhaustive process, therefore experts started to dig for new methods where your network automatically optimizes its architecture to increase the accuracy and performance of your model.
Various optimization methods were proposed, starting from RL approaches (Here and Here), Sequential model-based optimization (Here), Evolutionary method (Here), Bayesian optimization approach (Here), and Gradient-based models (Here). We will focus on two of the RL approaches.
1. Vanilla NAS

In this paper, the authors built a recurrent network to control the process of searching. To understand the process, we will narrow the search to perform image classification task using a convolutional network on CIFAR10 dataset. the RNN controller samples a “child” network’s architecture as a network description, build it, train it, and calculates its accuracy as a feedback signal. the accuracy is then fed to the controller as a reward to be optimized with RL method. the total process can be summarized as follows:
Generating a CNN child description with controller RNN
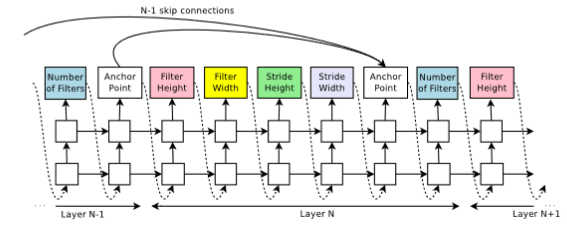
At this point, the RNN samples the hyperparameters of a child CNN description as a list of tokens, more specifically, the RNN predicts the number of filters, its filter’s height and width, stride’s height, and stride’s width per layer. once this description is carried out by a softmax classifier, the child network is built and trained. the accuracy theta is then fed to the controller.
This method was applied to an image classification task on CIFAR-10 and a language modeling with Penn Tree bank, but in this article, we will show the results of the image classification only.

Training with reinforce
To build an intuition about RL, please check this article (Here).
In our case, the list of tokens are fed to the controller as actions (a1:t), each action is then trained and its reward R is calculated. Since R is non-differentiable, we use iterative policy gradient method to optimize and update theta. Each action in the action space is set to have an initial probability of (1/t) to be chosen next iteration , however, in the policy gradient the probability of choosing an action (architecture) with higher reward next time is increased, meanwhile the probability of choosing actions with lower reward is decreased, thus the RNN controller generates better architectures over time. Noteworthy, in our case the controller itself is a policy network, the controller updates theta upon the following equation:

While “theta” is the accuracy of one child model, “a” is an action, “R” is the expected reward, and “b” is a bias to avoid high variance.
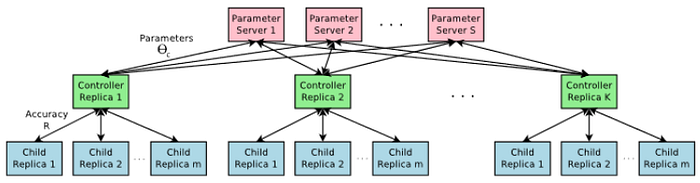
you might ask yourself, but what is m?, since the execution of such process would take a huge number of hours to train the networks, m is a number of GPUs that are used to parallelize the execution so the process would be much more efficient. The processing of the search is distributed over S number of servers, each server has controller replicas k, in the same way, each k replica trains m number of children, these replicas feed the accuracy theta of each trained child to the according server, and in the end the action with the highest reward is considered as the best candidate.
In this approach, the architecture’s complexity is increased by adding skip connections as anchor nodes, these anchor nodes are chosen with a set-selection attention mechanism. At layer N point which has N-1 content-based sigmoids to indicate the previous layers that need to be connected. these connections are specified by a probability distribution
Experiment and Results
The search space consists of convolutional architecture with ReLU, batch normalization, and skip connections between layers. for every convolutional layer, the controller has to decide a filter height in [1, 3, 5, 6], a filter width with [1, 3, 5, 7], and a number of filters in [24, 36, 48, 64]. For strides two sets of training were done, one with fixed 1 stride, and the other where the controller was allowed to choose from [1, 2, 3] strides.
The search was performed on S= 20 servers with K= 100 controllers and m= 8 replicas (in total 800 GPUs were used), with learning rate 0.0006, the weights were initialized between -0.08 and 0.08, and it was able to train 800 architectures simultaneously. Once the controller samples an architecture, the child network is being built and trained for 50 epochs. The reward which is used to update the controller is the maximum validation accuracy after the last 5 epochs. the validation set was 5000 instances while the other 45000 are used to train the model.
A total of 12800 child models were trained over 21–28 days of GPU time [source], the best architectures that this controller found were a DenseNet-BC (L=100 , K=40) with 190 layers depth, and 25.6M trainable parameters, this model achieved an error percentage of 3.46% which was state-of-art model on CIFAR-10. Another model would be considered regarding its lighter depth was NAS v3 max pooling and more filters with 39 layer depth, 37.4M trainable parameters and 3.65% error percentage.
2. Efficient Neural Architecture Search via Parameters Sharing (ENAS)
As mentioned in the vanilla NAS, 800 GPUs were used at a time in order to fasten the searching process, however, that is a huge computational complexity if you consider implementing this algorithm by your own. Therefore, researchers started to investigate novel and less expensive implementations.
In this paper, the main improvement was forcing all architectures to use the same weights, and eschew training each child model from scratch to convergence. Since utilizing weights differently at each training step of a new model is an exhaustive process, transferable learning can solve this problem. In the same way, we will discuss how to design a CNN for image classification task using ENAS, and how to apply for optimization.
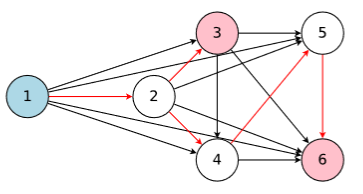
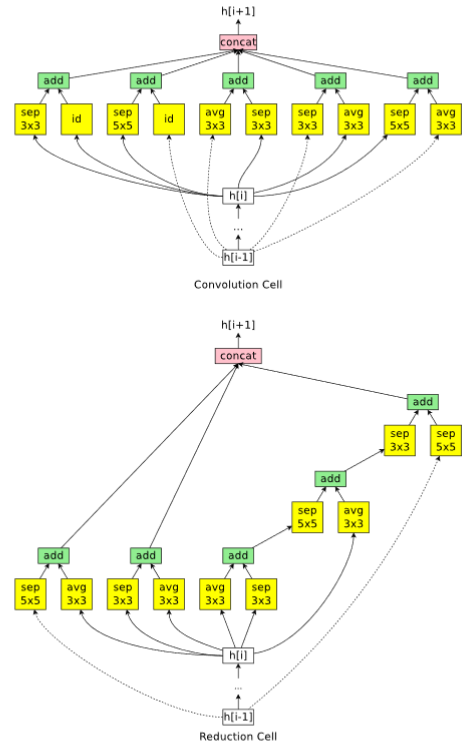
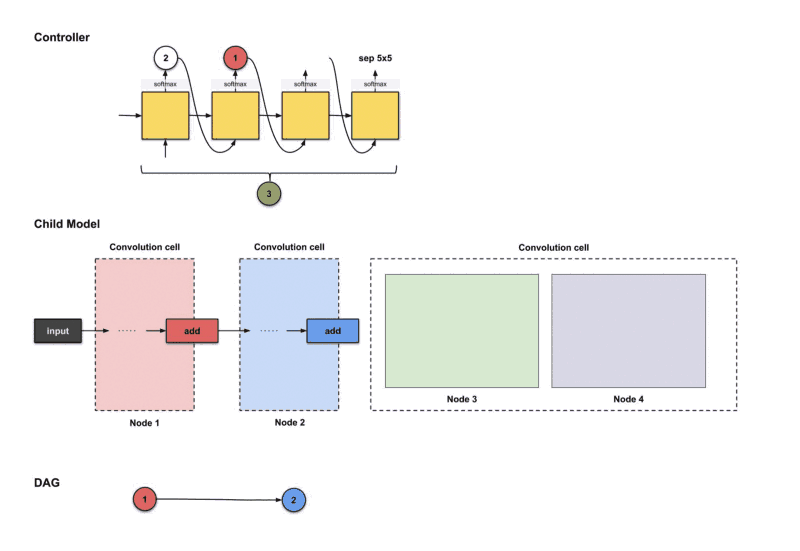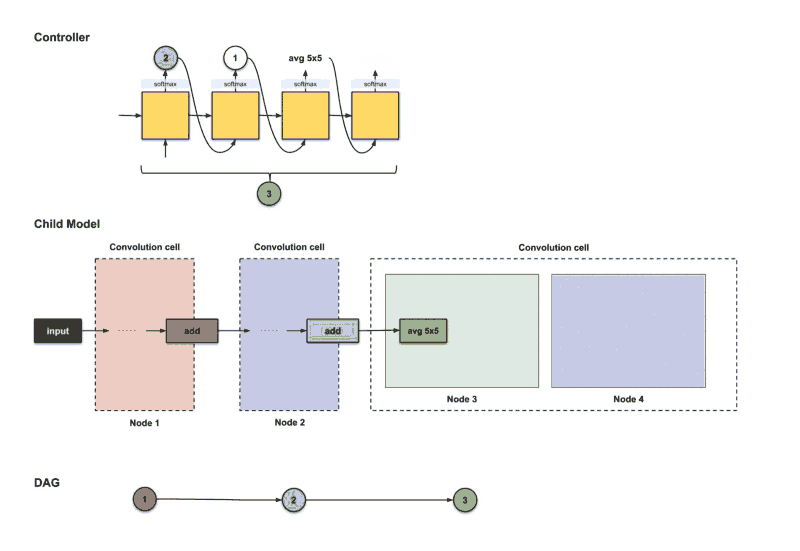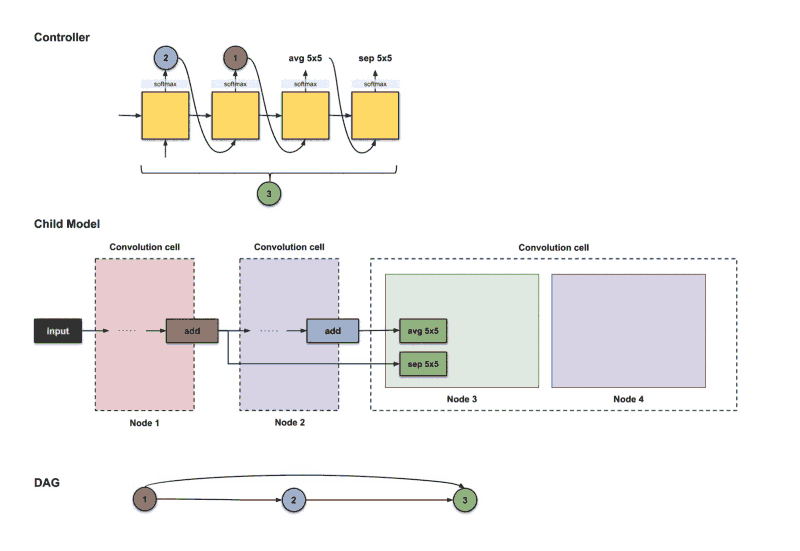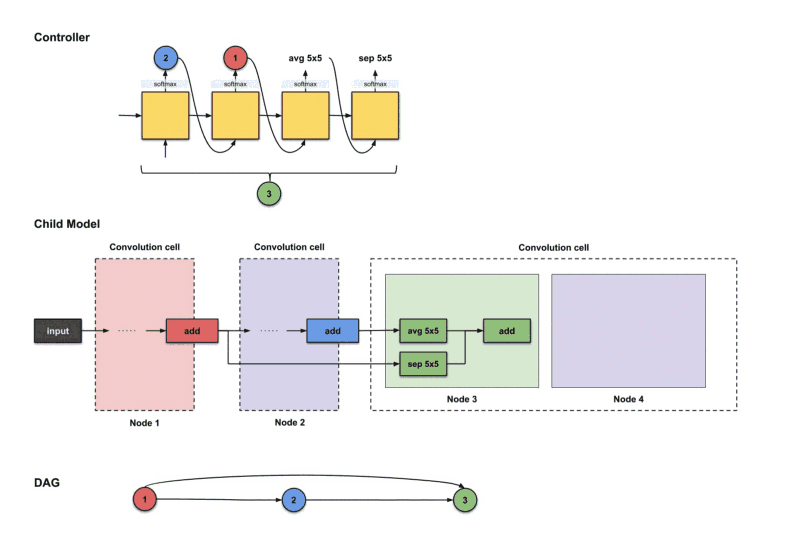
In ENAS, the main idea is that all of the architectures that NAS eventually iterates can be noticed as sub-graphs of a larger graph. more specifically, we can represent NAS’ search space using a single directed acyclic graph (DAG). In fig.6, this DAG represents the whole search space, however, the colored nodes are the only ones which were connected.
In essence of speeding up the search process, the controller samples a number of sub-networks (decisions) and train them on a smaller mini-batches of the data set. The sub-network with higher reward is considered, that means we are narrowing the search space, consequently, avoiding training of child networks that might not improve later. The controller follows an auto-regressive algorithm in sampling the decisions, which means the decision we sampled in the previous step is an input to the next step.
Two parameters were to be trained in ENAS, the first is the shared parameters w, and the second is the controller parameter theta for RL, training was done based on superposition. Updating the shared parameters was done after the pass of all the training data, however, the policy parameter is updated after each step of the controller. in other words, after each architecture is sampled. The gradient is computed using REINFORCE method with moving average baseline to reduce variance. and theta was computed on the validation set to avoid overfitting.
The search space for a CNN cell could be performed following one of two strategies:
- Micro search
- Macro search
According to (Here):
Macro search is an approach where the controller designs the entire network. Examples of publications that use this include NAS by Zoph and Le, FractalNet and SMASH. On the other hand, micro search is an approach where the controller designs modules or building blocks, which are combined to build the final network. Some papers that implement this approach are Hierarchical NAS, Progressive NAS and NASNet.
In Macro search, the controller has to make 2 decisions at each step (each layer):
- Which operation to choose.
- Which previous layer to connect.
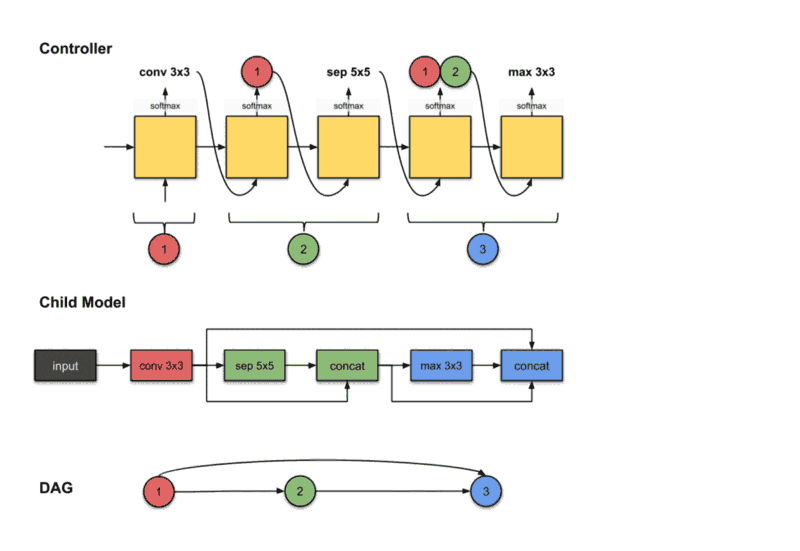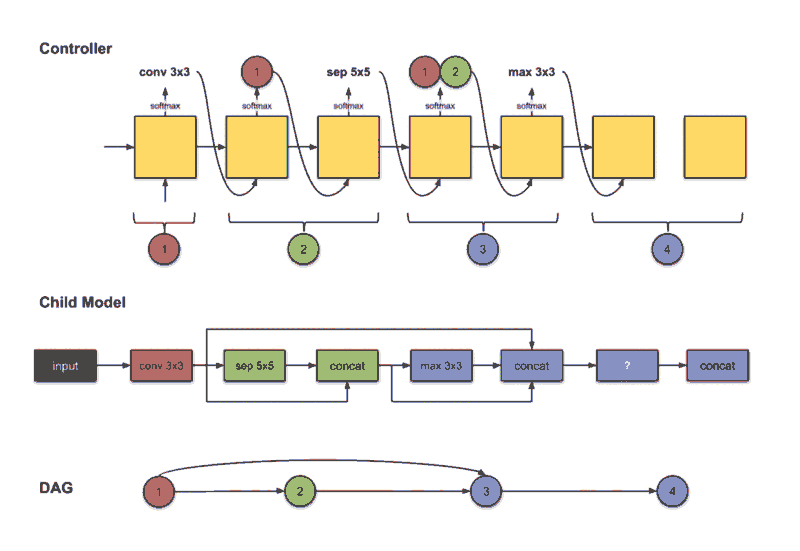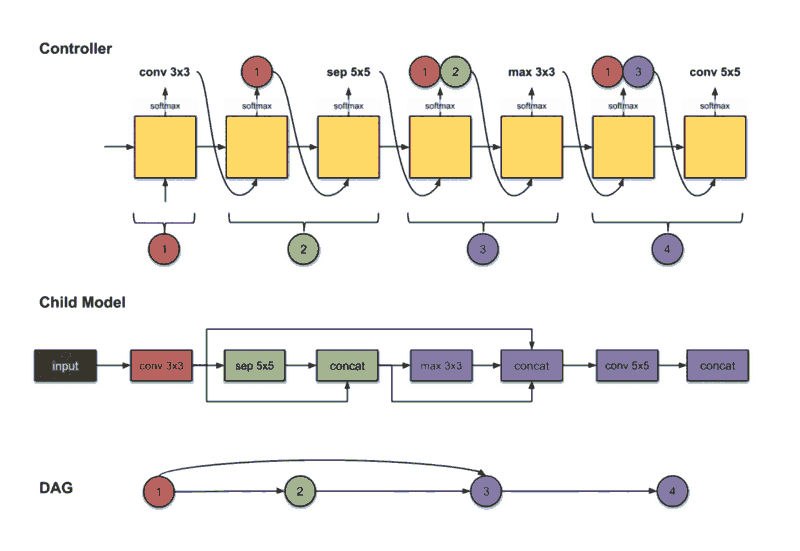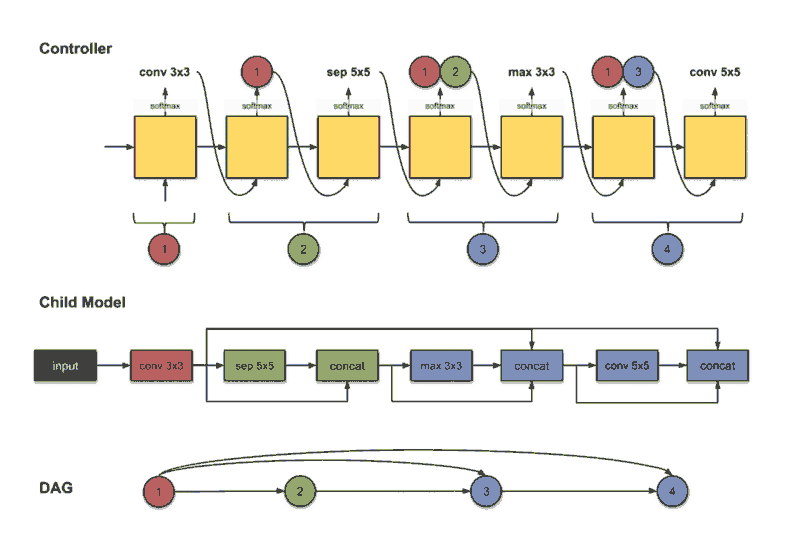
On the other hand in Micro search, the controller builds a B number of blocks, each block consists of N number of CNN cells. then connect it to other cells forming the final network in a transferable learning fashion. At each step, the controller has to decide which layer to connect, and which operation to choose.
ENAS Experiments and Results
In ENAS, CIFAR-10 was also used to perform an image classification task with 50000 instances for training and 10000 test examples. Macro and Micro search were applied. the learning rate varied between L= 0.001 to L=0.05 , each architecture was trained for 310 epochs with weight decay equals to 10^-4. Adam optimizer is used to optimize the policy. Only one GPU NVidia GTX 1080 was used in ENAS, which is impressive.
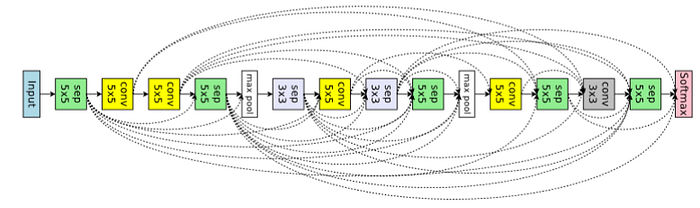
The training to 0.32 GPU days in Macro search, and 0.45 days for the micro search method, the best candidate in macro search achieved an error of 3.87% with 38.0 trainable parameters, meanwhile, the best micro search architecture challenged to 2.89% error rate with 4.6 trainable parameters. the results were state of the art comparing to other methods. Figure 9 and 10 show best architecture for image classification that ENAS found by macro and micro search respectively.