PIA project achievements at AIDO5
Author: Robert Moni
This year we competed with 6 different solutions at the 5th edition of the AI Driving Olympics (AIDO) which was part of the 34th conference on Neural Information Processing Systems (NeurIPS). There was a total of 94 competitors with 1326 submitted solutions, thus we proudly announce that our team ranked top in 2 out of 3 challenges.
The challenge
The AI Driving Olympics is an autonomous driving challenge with the objective of evaluating the state of the art for ML/AI for embodied intelligence. This year two leagues were deployed: the Urban Driving League that uses the Duckietown Platform, and the Advanced Perception League uses the nuScenes dataset/challenges and is organized by Motional.

We competed in the Urban Driving League which embodies three challenges we aimed to solve:

- Lane Following: in which the Duckiebot has to follow the right lane with no other objects on the road.
- Lane Following with Pedestrians: in this case, there are pedestrians represented by rubber ducks on the road and the Duckiebot has to avoid them while keeping a good lane following policy.
- Lane Following with other vehicles multibody: the submitted algorithm is submitted into multiple Duckiebots that run simultaneously on the track. The object is to do lane following while avoiding accidents.
Our top rankings
Our submissions ranked top in 2 out of 3 challenges. Even though the final results were based only on the result gained in the real environment at the competitions, we are satisfied with our results in the simulated environment.


Overall rankings in all 3 challenges with details.
Here are all of our rankings with more details.

You may note that in the real environment our agents perform poorly (i.e. travelled distance is very low). We think that this is due to a hardware upgrade done on the bots at the competition: a new series of duckiebots (DT19) is equipped with motors with embedded wheel encoders, while we trained our agent using a previous hardware edition (DT18) equipped with simple DC motors. Unfortunately, we weren’t aware of this hardware update until the last day of the competition, and it seems that nobody else was among the competitors.
Take a peek into our solutions
András Kalapos
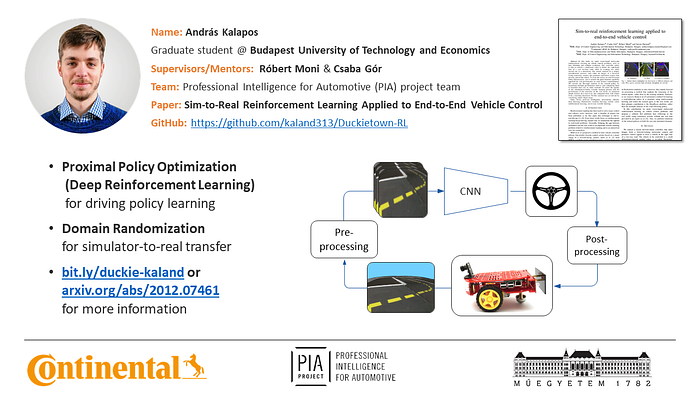
My solution at the 5th AI Driving Olympics uses a neural network-based controller policy that was trained using reinforcement learning. Its ‘brain’ is a convolutional neural network, that almost directly computes control signals based on images from the robot. Only very simple preprocessing is applied to the observations, such as downscaling, cropping and stacking. Then, based on this input, the network computes a single scalar value as its output that is interpreted as a steering signal.

An important feature of my solution is that I trained the agent only in a simulation, while also tested it in the real world. I trained it using a policy gradient type reinforcement learning algorithm, namely Proximal Policy Optimization for its stability, sample-complexity, and ability to take advantage of multiple parallel workers. To achieve robust performance in the physical environment I used domain randomization. This involves training the policy in a set of different variants the simulation, which are generated by randomly perturbing parameters of it, such as, lighting conditions, object textures, camera parameters and so on. The built-in randomization features of Duckietow’s official simulation proved to be sufficient for reliable lane following on the real roads of Duckietown, despite this simulation’s lack of realistic graphics and physical accuracy.
I developed my solution as part of my Master’s thesis, with the help of two supervisors, Róbert Moni and Csaba Gór. I am very grateful for their help and guidance! If you are interested in the details of our work, we published a paper about it, titled Sim-to-real reinforcement learning applied to end-to-end vehicle control.
András Béres
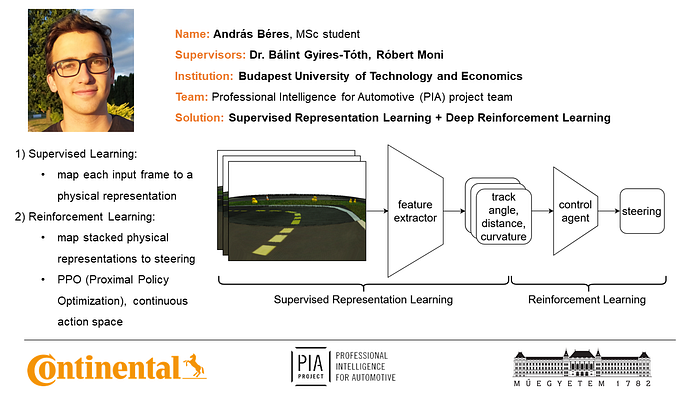
I divided the training into two stages, a supervised representation learning, and a reinforcement learning part. In the first stage, I trained a feature extractor on an offline dataset to encode each frame to a physical representation (track angle, distance and curvature). Then I froze the weight of the feature extractor and used it for compressing the observations for reinforcement learning in the simulator. I stacked multiple (3) input images and encoded them all to a physical representation, which enabled the agent to have a notion of the dynamics (the rate of change of the physical representations can be used to infer speed and angular velocity). Then I applied the Proximal Policy Optimization reinforcement learning algorithm to train a control network which outputs a steering signal based on the encoded input images. I used a continuous action space, and the StableBaselines3 reinforcement learning library.
Márton Tim
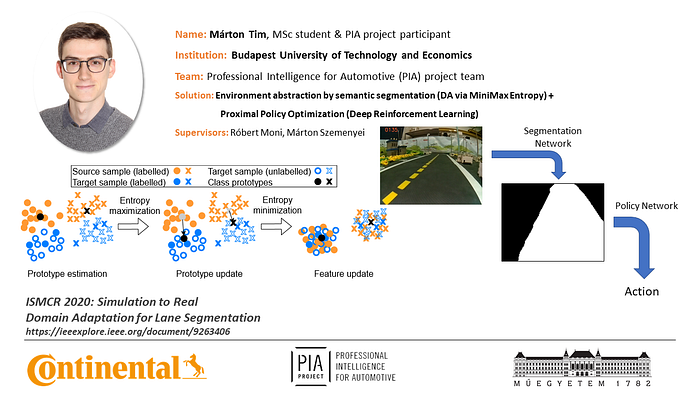
My solution incorporated a right lane segmentation tool, to preprocess raw observations into meaningful values. The segmentation model was a Fully Convolutional DenseNet, trained mostly on simulator data and domain adapted via the semi-supervised MiniMax Entropy method, and it required only 80 labelled real images to produce amazing results (over 98.5 IoU). Using segmented pictures as an environment abstraction, my chosen deep RL method (PPO) was able to learn how to drive fast in straight sections and how to take turns at high velocity. Further details about the applied sim2real method are provided in my paper published at ISMCR2020 titled Simulation to Real Domain Adaptation for Lane Segmentation.
Péter Almási
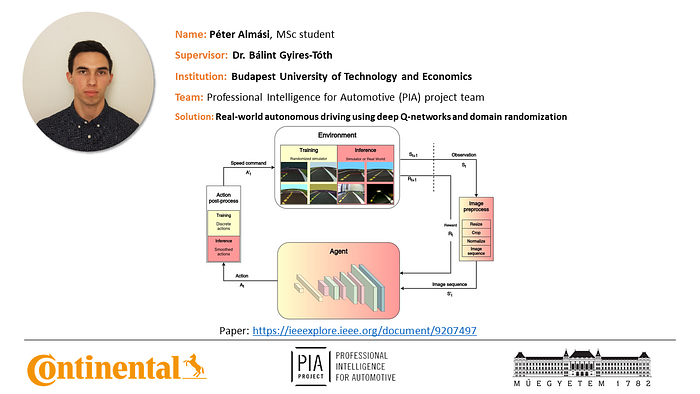
In my submission, I utilized a combination of deep reinforcement learning and sim-to-real technics. I used deep Q-networks to train an agent for lane following in the Duckietown simulator based on camera input. I applied domain randomization to train an agent that can control the robot both in the simulated and the real-world environment. Furthermore, I preprocess the images to make the training more stable and efficient and post-process the actions to make the movement of the robot smoother. Further details are provided in my paper published at IJCNN2020 titled Robust Reinforcement Learning-based Autonomous Driving Agent for Simulation and Real World.
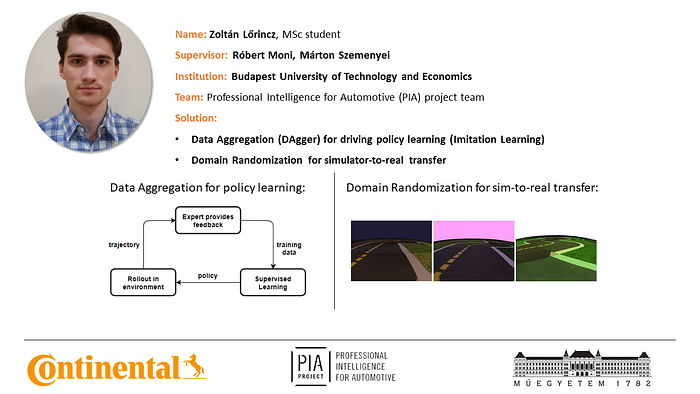
Zoltán Lőrincz
I applied Imitation Learning to solve the Duckietown lane following task in the AI-DO 5 competition.
The lane following agent was trained using the DAgger (Data Aggregation) algorithm, the imitated expert was a fine-tuned PID controller.
I used domain randomization during training to bridge the gap between the simulated and the real environment. Furthers details are available in my medium blogpost.
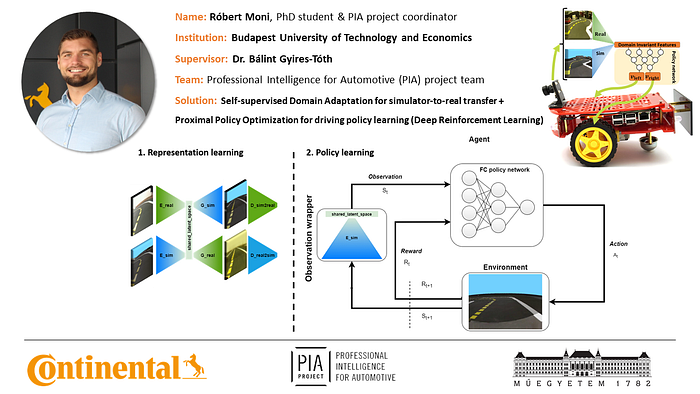
Róbert Moni
I divide the self-driving challenge into learning to see and learning to act. In the learning to see a part, I focus on the simulation-to-real transfer. I trained a deep neural network with a self-supervised domain adaptation method to learn image-to-image transformation between the domains (sim and real) while also learning domain invariant state representation. Thus the first part works as an encoder with the role to encode observations from either domain into a state. In the second part, learning to act, I train a deep neural network with a Deep Reinforcement Learning method named Proximal Policy Optimization to learn an optimal driving policy from the states produced by the encoder. Further details on my solution will be updated in this post after my paper on the subject is published.
Acknowledgement
Our project was supported by Continental Automotive Hungary Kft. via the cooperation project with Budapest University of Technology and Economics entitled Professional Intelligence for Automotive project.
