World models — a reinforcement learning story
Author: Robert Moni
Have you ever put your notebook under your pillow before an exam wishing that all that is written there will get consolidated into your long-term memory? I know a friend who did.
This article is about learning in dreams. More precisely desires to highlight the work of David Ha and Jürgen Schmidhuber in the field of deep reinforcement learning, sub-field model-based methods, presented at the Neural Information Processing Systems in 2018. Their paper entitled World Models demonstrates that their RL agent is able to learn by training in its own simulated environment. Their model was able to train an agent to play and gain high scores in the OpenAi Gym environment of Car Racing and the ViZDoom (DOOM with tuning for RL methods benchmarking) environment.
The model
Let’s jump right into it and have a look at the model. We have a basic RL setup: an environment in which an agent tries to learn a policy in a trial and error fashion to get the maximum reward possible.
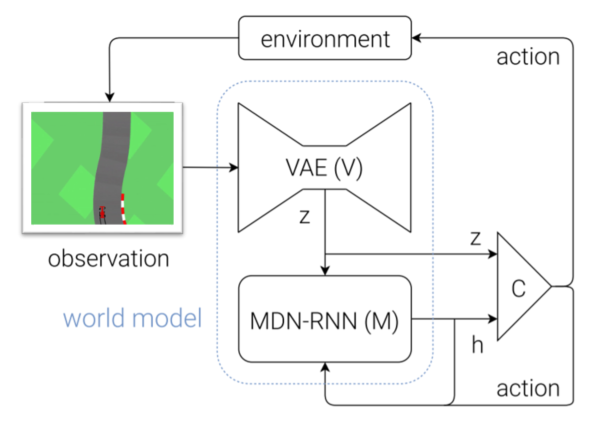
Step by step, with a case study on the Car Racing challenge, the model does the following:
- An observation is taken from the environment which is a 2D image by 64x64x3 dimension (width, length and the RGB depth).
- The observation is fed into the vision (V) model which is a Convolutional Variational Autoencoder (VAE) and encodes it into a latent vector z of size 32 .
- The following module is the memory (M). A Recurrent Neural Network with Mixture Density Network takes the latent vector z from the vision module, the previous action a chosen by the controller and the previous hidden state h of itself. Similarly to the vision module, it’s goal is to capture a latent understanding/observation of the environment by predicting what would the next z look like. Forward the hidden state h of the RNN of the length of 256.
- Finally the controller (C), a simple single layer linear model which maps the vision module’s observation z and the memory module’s hidden state h to an action at each time step. The output will be an action-vector of size 3 containing the quantitative representation of steering direction (-1 to 1), acceleration (0 to 1) and braking (0 to 1), e.g. [0.44, 0.6, 0]
So the World Model consists of three main parts and these are trained separately as the authors state. In the following, a separate description is provided for the three modules.
1. Vision
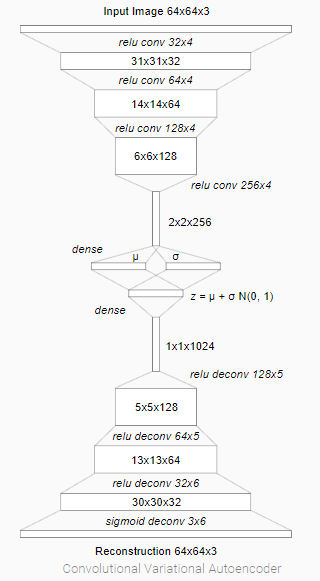
A Convolutional Variational Autoencoder (VAE)is trained for this module. VAEs are powerful generative models trained with semi-supervised learning. For a deep dive into VAEs I recommend you to read this post and follow this python tutorial done with Tensorflow on MNIST dataset. What is important for us is the latent vector z, which is sampled from a factored Gaussian distribution N with mean μ and diagonal variance σ. For each observation from the environment (image) the latent vector z is provided to the next model.
The encoding boosts the training process because the agent gets to see only the embedded representation of the input image.
2. Memory
The M model is basically a Long Short-Term Memory (LSTM) with 256 hidden states and with a Mixture Density Network (MDN).
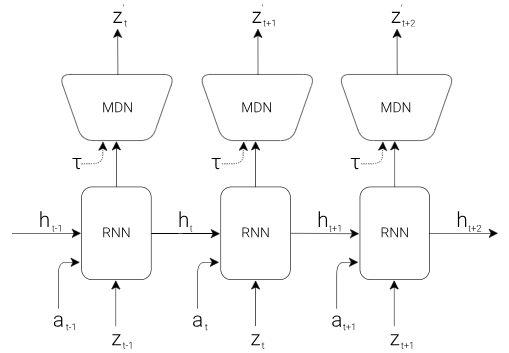
The M model attempts to predict what the next z value will be. This is fed to the MDN module which has the goal to introduce randomness. Basically, the MDN changes the output of the LSTM which is a deterministic z value into a range of possibilities for z.
3. Controller
The simple linear model which is trained to take the best decision is as follows:
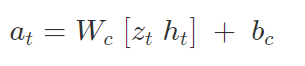
To find the optimal parameters for the controller (W[c] and b[c]), the Covariance Matrix Adaption Evolution Strategy (CMA-ES) algorithm is used. This was performed by using a population size of 64 CPUs, and each agent performed the task 16 times with different initial random seeds. By this, several variants of the controller were evaluated across the CPUs and the best parameters were chosen to be run in the actual environment.
This setup worked well on the Car Racing environment where the goal was to have at least an average of 900 points over 100 trials.
Does it really learn in its “dream”?
Now back to the dreaming part. That was an experiment performed in the DOOM environment. It has somehow a different setup, tailored for that environment, considering different image input size and the fact that the agent can die.
The fundamental contribution (which actually got hyped with the story that the agent learns in its “dream”) consists in the demonstration of that training the agent using the predicted z latent representation produced by the M model, got a better score while playing the DOOM. The M model learns to generate monsters that shoot fireballs at the direction of the agent, while the C model discovers a policy to avoid these generated fireballs. The V model is only used to decode the latent vectors z produced by M into a sequence of pixel images.
Run the method
Many thanks to Fábián Füleki who put together for experimentation a docker image running on Linux host machine. The GitHub repository can be found here, and make sure you are running a system equipped with a CUDA capable GPU, and you have installed docker, nvidia-docker a CUDA 9.0.
Steps to follow:
1. Setting up the docker
a. By pulling the image from dockerhubdocker pull ffabi/gym:90b. By building it locallygit clone https://github.com/ffabi/SemesterProject.gitcd SemesterProject/docker_setupdocker build -f Dockerfile_cuda90 -t ffabi/gym:90 .2. Running the docker containermkdir ./ffabi_shared_foldernvidia-docker create -p 8192:8192 -p 8193:22 -p 8194:8194 --name / ffabi_gym -v $(pwd)/ffabi_shared_folder:/root/ffabi_shared_folder / ffabi/gym:90nvidia-docker start ffabi_gymdocker exec -it ffabi_gym bash3. Clone the implementation of the World Models conceptcd ffabi_shared_foldergit clone https://github.com/ffabi/SemesterProject.gitcd SemesterProject/WorldModels4. Running the applicationmkdir dataxvfb-run -a -s "-screen 0 1400x900x24" python3 01_generate_data.py car_racing --total_episodes 200 --start_batch 0 --time_steps 300xvfb-run -a -s "-screen 0 1400x900x24" python3 02_train_vae.py --start_batch 0 --max_batch 9 --new_modelxvfb-run -a -s "-screen 0 1400x900x24" python3 03_generate_rnn_data.py --start_batch 0 --max_batch 9xvfb-run -a -s "-screen 0 1400x900x24" python3 04_train_rnn.py --start_batch 0 --max_batch 0 --new_modelxvfb-run -a -s "-screen 0 1400x900x24" python3 05_train_controller.py car_racing --num_worker 1 --num_worker_trial 2 --num_episode 4 --max_length 1000 --eval_steps 25
Conclusion
All Models Are Wrong, Some are Useful (George Box, 1976)
The World Model by David Ha and Jürgen Schmidhuber is definitely a useful model, which is capable of learning the environment and to teach the agent to perform well in it. This work provides a good explanation of how our brain processes information in order to take decisions for actions, thus serves as an excellent framework for future studies in model-based methods.
References
Paper’s blog post:
GitHub repository:
2 other exiting usage of the Word Model:
Links for VAE:
The original post can be found on Robert’s personal medium page: https://medium.com/@robertmoni_66330/b5611c590e6e
